Software Architectural Styles
Software-Architecture ·A brief overview about the main software architectural styles and why and when we use them.
Language-based Systems
The programing language you choose to build your software will define the way you will architect it due their limitations or advantages.
For instance, a OOP (i.e. Java) will probably give you a better domain abstraction than a procedural language (i.e. C), but you cost you more performance and wont work for embedded software.
Abstract Types and Object Oriented
Using a OOP paradigm we have better application of “Abstraction”, “Encapsulation” and “Decomposition” principles. The code produced can better translate the business language and generally the learning curve is smaller. High-level programing languages generally are intuitive and have lots of third-party libraries that already solve common problems.
The cons is that it generally implies less performance and higher computational power is required. It is more difficult (and impossible sometimes) to create lightweight or embedded software with this paradigm.
Usages:
- Management and administrative systems.
- Web apps.
- Mobile apps.
Main program and Subroutines
This paradigm consists in usage of procedural code based on routines and subroutines sharing globals variables and procedures. It advantage is a very lightweight and highly performative software that consumes less computational power and energy. The cons is that is really difficult to maintain and the learning curve is higher. Low-level programing languages are generally not intuitive at all do not translate well the business language.
Usages:
- Embedded software.
- Computational focused systems.
Repository Based Systems
When it is needed to shared data within modules and components an often used solution is a Data Centric Software Architecture.
Databases
At the core of a Data Centric architecture are 2 different types of components:
Central Data: Stores and share data across all the components that connect to it.
Data Accessors: They are the components that connect to the Central Data component. These run queries, transactions to store and retrieve data from the Database.
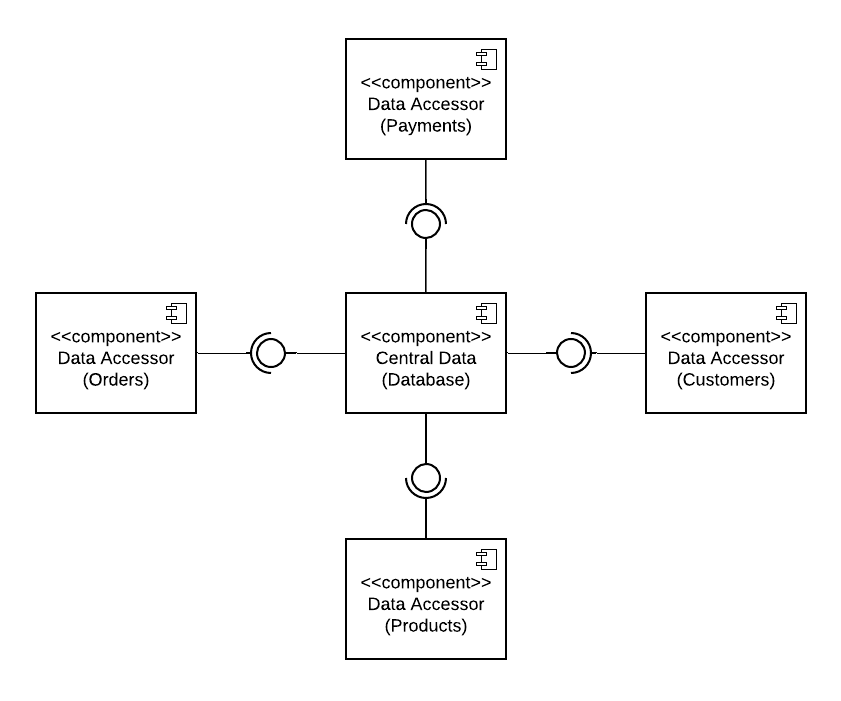
The main benefits of a data centric architecture style, besides share data are:
- Data Integrity: Data will be store with proper normalization and will be accurate.
- Data Backup: Data containing the current state of the system can be saved to be used later.
- Data Restoration: System state can be restored through backup.
- Data Persistence: Data will keep alive to be used later.
- Central Data is Passive: The main focus is storage, so the business rules stay in the application level.
But some disadvantages of a data centric architecture are:
- System rely on a single data source, that, if fails, compromise all the applications.
- Difficult to change schema, cause it is being used for many components.
- As the data is used by many places, the overload of one application can affect all the others.
Layered Systems
In the real world when we need to send or receive some information, we may need to talk to representatives instead of directly communicate with the final receivers. This way we guarantee the information will arrive in a standard way and we can continue focusing on our main work, emphasizing the separation of concerns.
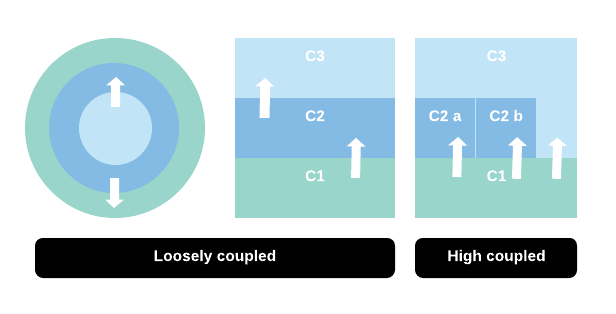
When we have a layered architecture the components are only allowed to talk to adjacent components. So they do not know about upper or lower layers of the system. With this we ensure our applications will be loosely coupled and their state will not affect or be affected directly by other applications.
Client Server n-tier
Layered architecture is about make components loosely coupled and restricting their communication within only adjacent layers.
The n-tier or multi-tier happens when this components are also separated by being located in separate machines. So their performance, computational power consumption and environment requirements will not directly affect each other. Also other benefits like load balancing and autoscaling are benefited by a multi-tier architecture.
The relation between client and server components in a multi-tear architecture can occur in an synchronous our asynchronous way using events, web sockets and request/response handlers.
Advantages
- Scalable: As components are distributed in different servers, it is possible to farm them and increase application capacity using techniques like load balancing and autoscaling.
- Centralization: Centralized functionalities and computational power only to the relevant components.
- Distribution of computational power: Only necessary application servers need to have specific hardware. It can scales horizontally if needed.
Disadvantages
- Ad complexity do infrastructure management.
- Ad complexity to data synchronization.
- Demands extra resource to manage client/server relationships.
Interpreter-based systems
Interpreters
Interpreters are programs that read and execute code provided by the user. The user does not need to know how the underlying logic of the interpreter, just the right code to provide.
Interpreters are used to execute Scripts os Macros. Examples os Interpreter-based systems are:
- Google Chrome: Where you can create your extension using Javascript to customize or add features to the browser.
- Microsoft Excel: The Excel formulas are core instructions that will be executed by it internal interpreter. The user does not know how the interpreter works, just how to declare the functions correctly.
State Transition Systems
This is actually a concept to describe all potential behaviors a system can have, does not matter they have a low probability to happen, a State Transition will describe how to reach that state.
Terminology:
-
State: It is a information the system remembers. Example: An e-commerce system can have the states: “Empty cart”, “Full cart” or “Under Checkout” states.
-
Transition: Defines the transition from one state to another. We have a non-deterministic transition when from on state, multiple states are possible.
-
Behavior: Describes what the system will do when arrive to a condition. This can be determined by user input, events or time.
Some practical usage example is how operational systems manage resource allocation using state machine and multithread.
DataFlow Systems
A data flow architecture treats the system as a series of transformations in a data set.
Pipes & Filters
The pipes are the channels from which the date flows from a filter to another.
The filters are responsible to receive the input from the Pipe, transform it and follow to another Pipe, that will follow to another Filter and so on.
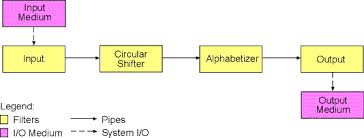
Advantages:
- Loosely coupled architecture.
- Better maintainability, flexibility and scalability.
Disadvantages:
- Become slower as more filters and pipes are added.
- Since the filters are loosely coupled and independent, redundancy can happen.
Implicit Invocation Systems
Event-Based
Derived from the Event-Driven paradigm, the Event Based Architecture happens when functions are executed trigged by Events, that could be inputs, signals, messages or data coming from other functions or programs. These Events are created by and Event Generator and listened by an Event Consumer or Subscriber.
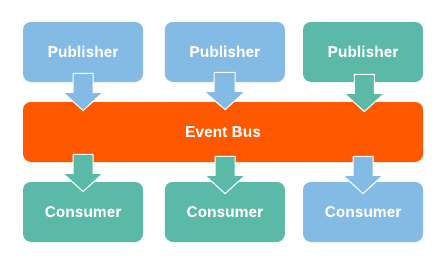
Event generators: Generate and send the messages to be processed. Event consumers: Receive the messages to be processed and process them.
The communication between Event Generators and Event Consumers is not direct, being called “Implicit Invocation”. This intermediation is done by a “Event Bus”.
When working with event based is important to be aware of race conditions to avoid undesired results when shared data is not updated correctly.
For instance, when one event updates a resource before a previous event that also updates the same resource was executed. To solve this there are some techniques like semaphores and message acknowledgement.
Publish Subscribe
Different of Event-Based architecture, “Publish Subscribe” systems enforces that components should be either publishes or subscribers, but never both. Also the relationship between Publisher and Subscriber can vary in form and closeness.
Publishes and subscribers are not explicitly related, so they are also following Implicit Invocation. Examples are:
- RSS Feed.
- Mail lists.
- Mobile messages subscriptions.
Process Control Systems
Control is important for many types of process in order to know they will operate in a safe way and achieve the expectations with efficiency.
Process Control
One of the techniques of process control is called Feedback Loop. It consists in some elements (Let’s take a water level control system):
- Sensor: Monitor important information to be checked. I.e. Sensor to detect water volume.
- Controller: The logic to check the information monitored and act accordingly. I.e. Check water volume and increase / decrease volume.
- Actuator (or effector): How the manipulate the process. I.e. A Water pump (increase / decrease the water level).
- Process: What is being controlled. I.e: Water tank.
- Set Point: The desired state of the process. I.e: 5 cubic meters of water.
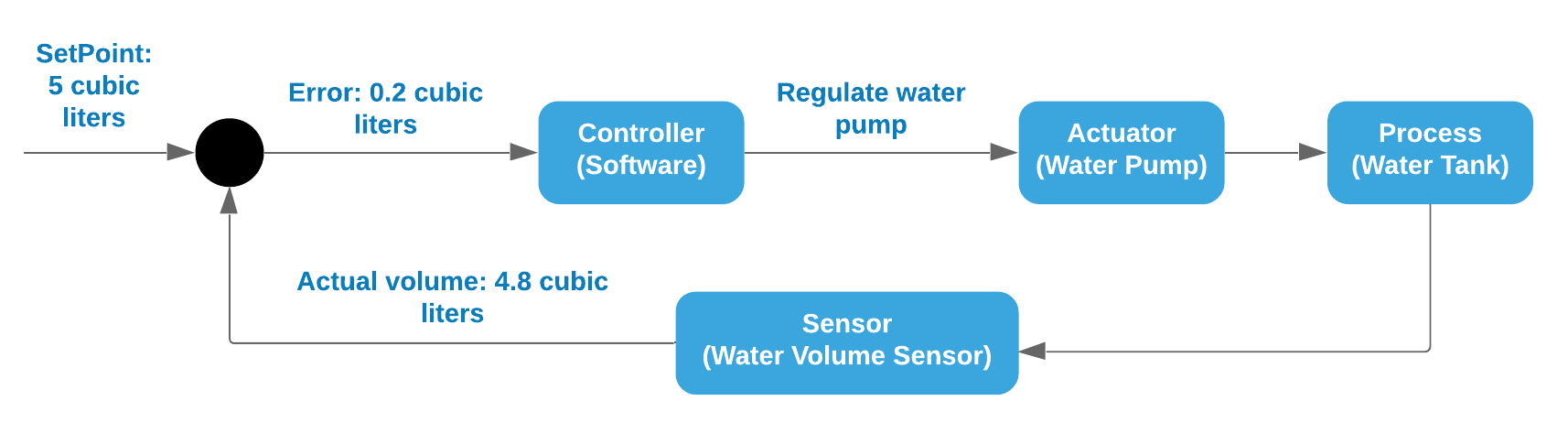
In this case the Feed-back loop runs continuously monitoring the water volume based on the set point and adjusting the water pump (open / close) to maintain the water volume.
Another process control technique, commonly used for more complex process controls is the MAPE-K.
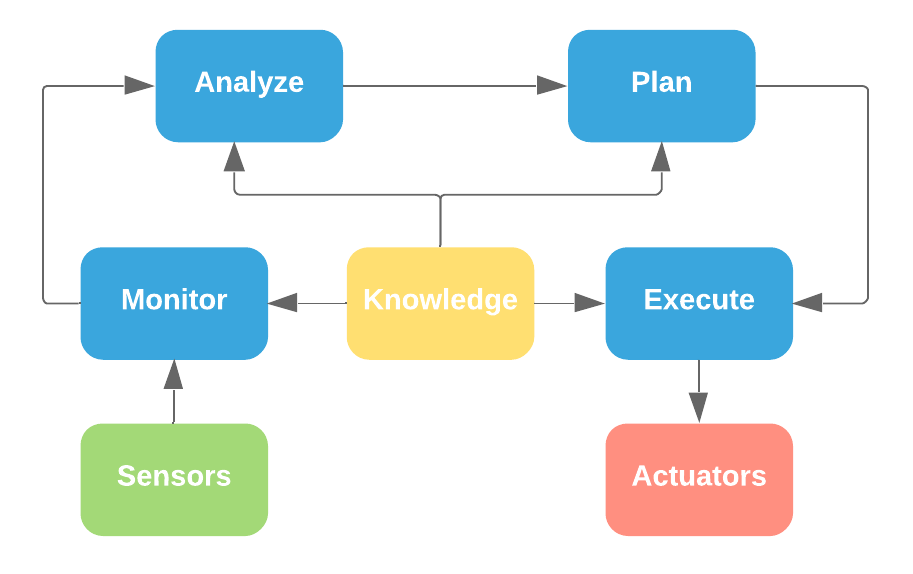
In this technique all the steps must have knowledge of the process state.
The MAPE-K technique is used for instance on self-driving cars software in combination with machine learning and big data to help in the analyze and plan steps.
The new steps here are:
- Monitor: Check the state and other metrics provide by the sensors, beside the current state of the process.
- Analyze: Evaluate metrics according to system configurations, set points, etc.
- Plan: This part the system needs to understand what is happening to know which action to take to reach the desired result. This can be done using machine learning, big data or some AI techniques.
- Execute: Update the process based on previous analyze and plan.